Implementation
Building on our cache modeling basics, let's look at a practical implementation using C++.
A cache consists of 2 components:
data store- which holds the actual datatag store- which holds metadata about the data (like tags, valid bits, etc.)
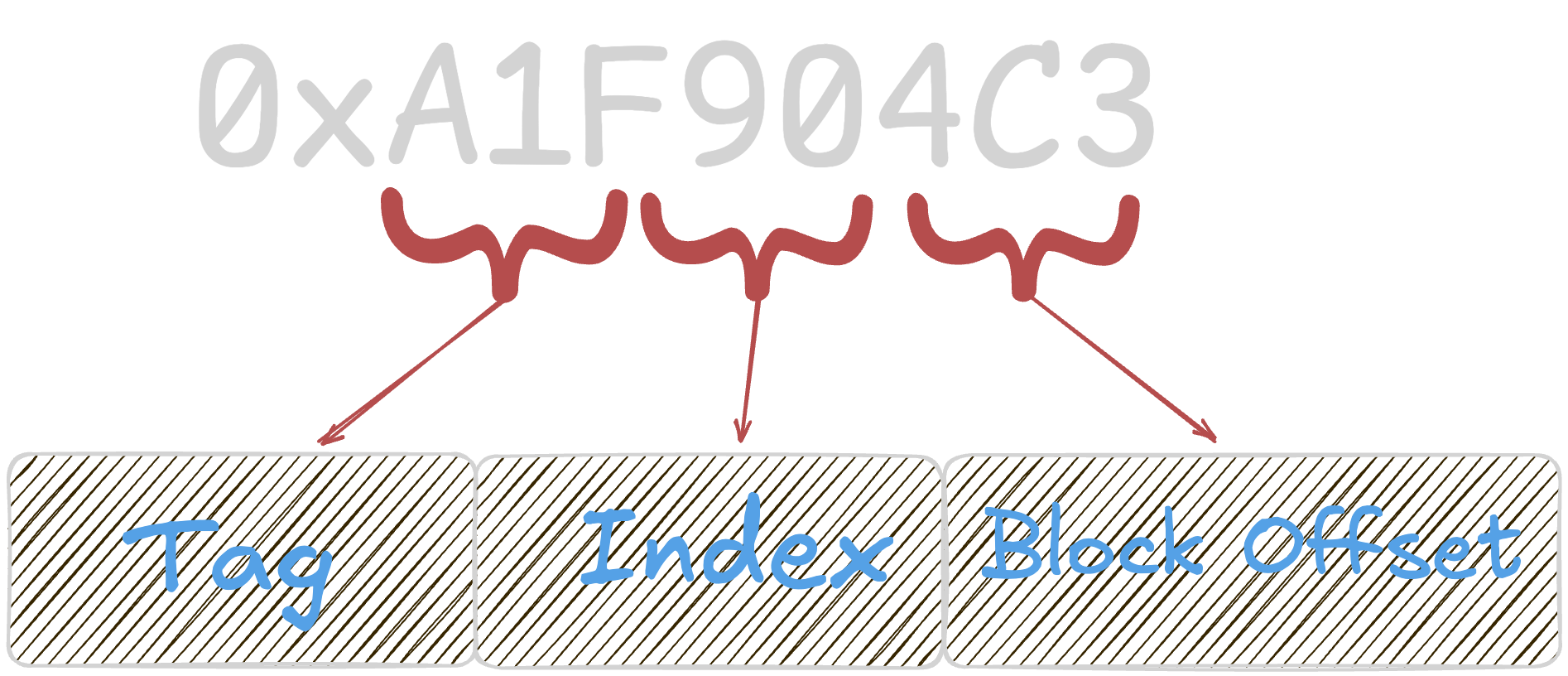
The address generated by the CPU is divided into 3 parts:
block offset- which specifies the exact location of the data within a blockindex- which specifies the set in the cache where the block can be foundtag- which is used to identify if the data in the cache corresponds to the requested address
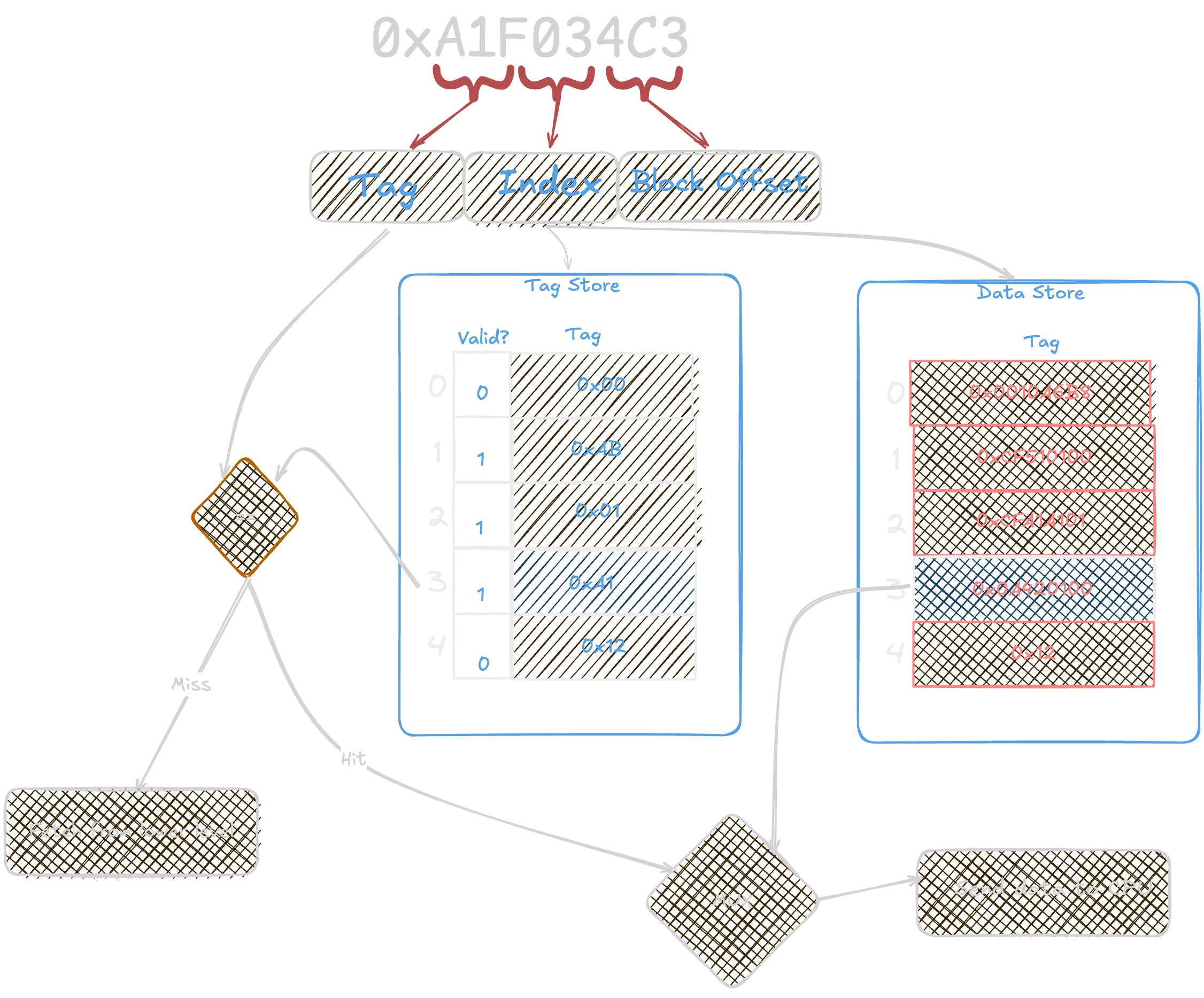
Flow
When the CPU requests data for a memory address:
The cache checks its
tag storeto see if the data is present (ahit) or not (amiss). - If it's a hit, the data is fetched from thedata store.If it's a miss, the cache fetches the data from the next level of memory (like RAM) and updates both the
data storeandtag store.
Structure
Let's start by defining a generic class cache.
A cache
Line, can be defined as follows:Here,
validindicates if the line contains valid data, andtagis used to identify the data block.We use a
vectorofliststo represent thetag store, where eachlistcorresponds to a set in the cache. This allows us to easily implement different replacement policies like LRU (Least Recently Used) by manipulating the order of elements in the list.
struct Line{
bool valid = false;
uint32_t tag = 0;
};
std::vector<std::list<Line>> tagStore;We can include key cache parameters like
block size,number of sets,number of ways, etc. in theCacheclass.Metrics like
number of references,number of misses,hit latency, etc. are helpful for performance analysis.cacheclass should also include methods like:Constructor
an
accessfunction for tagStore accessinvalidating entries(inlclusivity)
Now, putting all of it together:
Header file
class Cache{
//------------------------------------//
// Cache Configuration //
//------------------------------------//
int nWays;
int nSets;
int blockSize;
int memSpeed=0;
bool inclusive=false;
Cache* nextLevel=nullptr;
std::vector<Cache*> prevLevels = {nullptr};
int missLatency;
int n_block_bits;
int n_idx_bits;
//------------------------------------//
// Cache Metrics //
//------------------------------------//
int hitLatency;
int Refs=0; // references
int Misses=0; // misses
int Penalties=0; // penalties
//------------------------------------//
// Cache Methods //
//------------------------------------//
Cache(int hitLatency, int nWays, int blockSize, int nSets, int memSpeed, bool inclusive);
int access(uint32_t address);
void invalidate(uint32_t invalidate_address);
void parse_address(uint32_t& blockOffset, uint32_t& index, uint32_t& tag, uint32_t address);
};Now that we have a generic cache class, we can define iCache, dCache and l2Cache to inherit from it.
The constructors of these derived classes call the base class constructor with appropriate parameters. You can also see the the
l2Cachetakes in amemSpeedparameter, this is the lowest level that talks to DRAM
class iCache : public Cache{
public:
iCache(int hitLatency, int nWays, int blockSize, int nSets);
};
class dCache : public Cache{
public:
dCache(int hitLatency, int nWays, int blockSize, int nSets);
};
class l2Cache : public Cache{
public:
l2Cache(int hitLatency, int nWays, int blockSize, int nSets, int memSpeed, bool inclusive);
};Creating a Cache Hierarchy
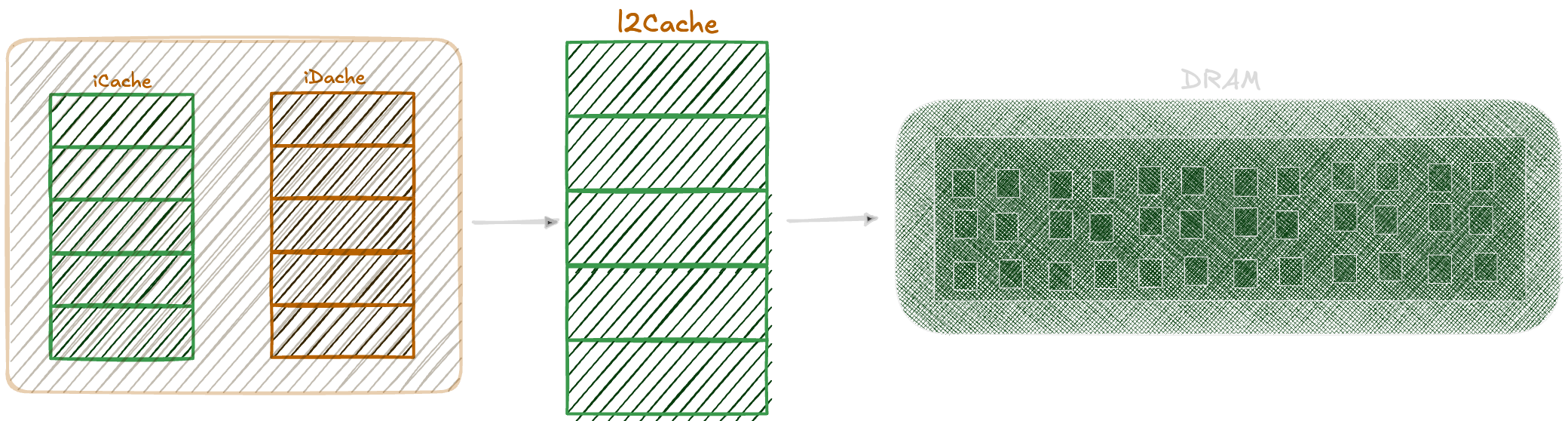
For the already curious minds out there wondering how do we establish a cache hierarchy, here's a simple example:
Cache* l2C = new l2Cache(50, 8, 64, 16384, 100, true);
Cache* dC = new dCache(2, 4, 64, 256);
Cache* iC = new iCache(2, 2, 64, 512);
l2C->nextLevel = nullptr;
l2C->prevLevels = {dC, iC};
dC->nextLevel = l2C;
dC->prevLevels = {nullptr};
iC->nextLevel = l2C;
iC->prevLevels = {nullptr};which will create a structure as shown below:
I think of the
nextLevelandprevLevelsmutation as a "hack" since the respective pointers to objects are available only after their s declaration so I cannot pass them into respective the constructors.
The access method is the heart of our cache simulation. It handles both hits and misses, updates metrics, and manages access to the next memory level.
Helper Functions
parse_address(blockOffset, index, tag, address);
for(auto i=set.begin(); i!=set.end(); i++) {
if (i->valid && i->tag == tag) {
Line hitLine = *i;
set.erase(i);
set.push_front(hitLine);
return hitLatency;
}
}
missLatency = nextLevel ? nextLevel->access(address) : memSpeed;It also calculates the address to be invalidated in the previous level if the cache is inclusive.
auto &invalidate_line = set.back();
if(inclusive && invalidate_line.valid){
uint32_t invalidate_idx = index;
uint32_t invalidate_tag = invalidate_line.tag;
uint32_t invalidate_address = (invalidate_tag << (n_block_bits + n_idx_bits)) | (invalidate_idx << n_block_bits);
for(auto i:prevLevels){
// cout << "triggering invalidation from l2 for addr: " << invalidate_address<< endl;
if(i) i->invalidate(invalidate_address);
}
}I'll leave the implemenation of parse_address and invalidate methods as an exercise for the reader.
Testing
For testing, I have been using traces from this repository which you can run using bunzip2 -kc ../traces/trace.bz2 | ./cache_sim.o where cache_sim.o is the compiled executable. You can have the BLOCK_SIZE, N_SETS, N_WAYS, HIT_LATENCY, MEM_SPEED, INCLUSIVE as command line arguments or hardcode them in the main function.
I have also dumped the key metrics like number of references, number of misses, miss rate, miss penalty, AMAT, so the output looks something like:
Cache Statistics:
total I-cache accesses: 15009377
total I-cache misses: 30990
total I-cache penalties: 1952100
I-cache miss rate: 0.21%
avg I-cache access time: 2.13 cycles
total D-cache accesses: 4990623
total D-cache misses: 37896
total D-cache penalties: 5084000
D-cache miss rate: 0.76%
avg D-cache access time: 3.02 cycles
total L2-cache accesses: 68886
total L2-cache penalties: 3591800
total L2-cache misses: 35918
L2-cache miss rate: 52.14%
avg L2-cache access time: 102.14 cycles
total compulsory misses: 35918
total other misses: 68886
Total Memory accesses: 20000000
Total Memory penalties: 47036100
avg Memory access time: 2.35 cyclesThis is a good time to stop and reflect on what we have built so far. We have a basic cache simulator that can model different cache configurations and hierarchies.
In the next blog, we explore more advanced topics like prefetching strategies.