Introduction
Prefetching is a technique used to improve cache performance by predicting future memory accesses and loading data into the cache before it is actually requested by the CPU. This can help reduce cache misses and improve overall system performance.
Hardware data prefetching works by predicting the memory access pattern of the program and speculatively issuing prefetch requests to the predicted memory addresses before the program accesses those addresses.[1] We say that prefetching can effectively hide the latency of memory accesses and improve performance if:
The memory access pattern is correctly predicted
Prefetch request is issued early enough, but not too early that the prefetched data just sits in the cache(even worse: it gets evicted before it is used.)
The data arrives
just-in-timefor the program to access the data,
I like to quote an example of ordering food while leaving for home from work.
If you order food just as you reach home, you will have to wait for the food to arrive. But if you order food while leaving work, by the time you reach home, the food will be there waiting for you.
But prefetching can negatively impact the performance:
predicted memory addresses are not accurate
Can increase the contention for the available memory bandwidth
Prefetched data can evict useful data from the cache
Prefetcher design is
Aggressive and issues too many prefetch requests, leading to increased memory traffic and cache pollution.
Conservative and misses opportunities to prefetch useful data(lags behind).
Prefetching Strategies
There are several prefetching strategies, including:
Next-line prefetching: This strategy prefetches the next sequential cache line when a cache line is accessed. This is effective for workloads with sequential access patterns.

Current address is then prefetch into L1.
Stride prefetching: This strategy detects regular strides in memory access patterns and prefetches data at those strides. For example, if a program accesses memory addresses 0, 4, 8, 12, etc., the prefetcher can detect this pattern and prefetch the next address in the sequence.

Current address is then prefetch into L1, where N is the detected stride.
Stream prefetching: This strategy detects streams of memory accesses and prefetches data for the entire stream. This is effective for workloads with streaming access patterns, such as multimedia applications and there can be multiple streams.

Prefetcher Knobs
The aggressiveness of a prefetcher can be controlled by:
Prefetch Distance which is how far
ahead of the current accessthe prefetcher should fetch.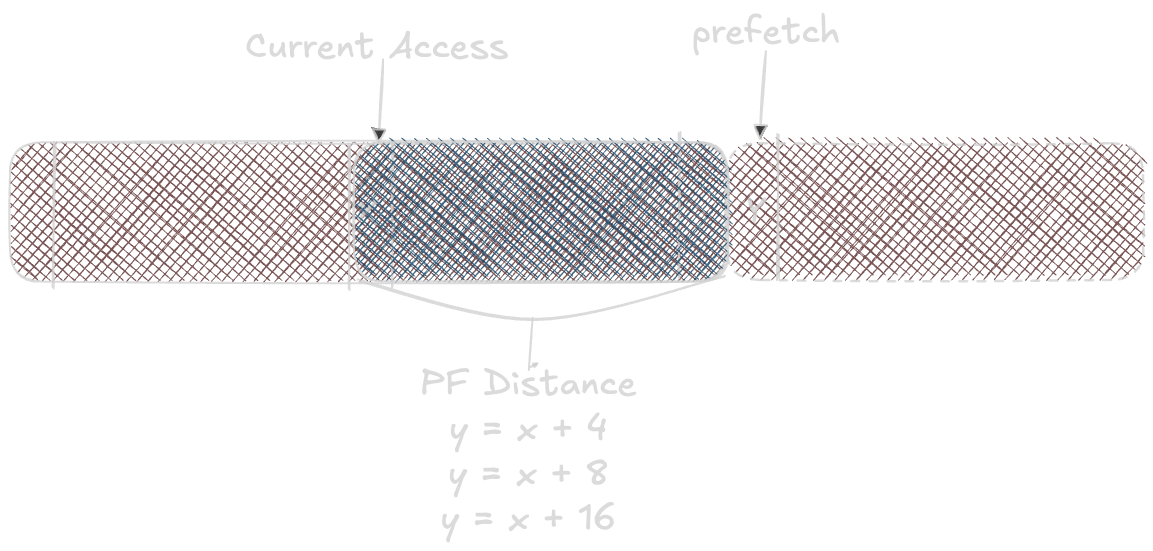
Prefetch Degree is the number of cache lines to prefetch for each access.

Based on the above knobs, 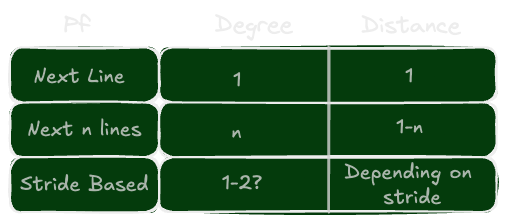
Metrics of Prefetcher Effectiveness
Prefetch Accuracy: Prefetch accuracy is a measure of how accurately the prefetcher can predict the memory addresses that will be accessed by the program. It is defined as:
where Number of Useful Prefetches is the number of prefetched cache blocks that are used by demand requests
Prefetch Lateness: Prefetch lateness is a measure of how timely the prefetch requests generated by the prefetcher are with respect to the demand accesses that need the prefetched data.
A prefetch is defined to be late if the prefetched data has not yet returned from main memory by the time a load or store instruction requests the prefetched data(Even though the prefetch requests might be accurate).
Prefetcher Generated Cache Pollution: A demand miss is defined to be caused by the prefetcher if it would not have occurred had the prefetcher not been present.
If the prefetcher-generated cache pollution is high, useful data in the cache could be evicted by prefetched data.
High cache pollution can require the re-fetch of the displaced data from main memory.
Implementation
If you recall, we implemented a generic Cache class in the previous blog post. We can extend that class to include a prefetch function.
void prefetch(uint32_t address_ptr, char* i_or_d, char* r_or_w);The prefetch function does the following:
Calculate the
prefetch_address(es)based on the prefetching strategy eg: for next-line prefetching, it would be
address_ptr + blockSize
Check if the
prefetch_addressis already present in the cache (to avoid redundant prefetches)If not present, access the next level of memory to fetch the data into the cache
Update the cache's tag store and data store accordingly
and then for each access to the cache, we can call the prefetch function.
if (prefetch) iCache->prefetch(pc, &i_or_d, &r_or_w);
if (prefetch) dCache->prefetch(address, &i_or_d, &r_or_w);Results
Using the prefetch function for both I-cache and D-cache, we can benchmark the performance of our cache model with and without prefetching. We can use the same traces as before and compare the metrics like:
| Metric | No Prefetching | Next Line PF |
|---|---|---|
| total I-cache accesses | 15,009,377 | 15,009,377 |
| total I-cache misses | 30,990 | ↓ 16,009 |
| total I-cache penalties | 1,952,100 | ↓ 922,450 |
| I-cache miss rate | 0.21% | ↓ 0.11% |
| avg I-cache access time | 2.13 cycles | ↓ 2.06 cycles |
| total D-cache accesses | 4,990,623 | 4,990,623 |
| total D-cache misses | 37,896 | ↓ 9,964 |
| total D-cache penalties | 5,084,000 | ↓ 718,400 |
| D-cache miss rate | 0.76% | ↓ 0.20% |
| avg D-cache access time | 3.02 cycles | ↓ 2.14 cycles |
| total L2-cache accesses | 68,886 | ↑ 113,925 |
| total L2-cache misses | 35,918 | ↑ 38,085 |
| total L2-cache penalties | 3,591,800 | ↑ 3,808,500 |
| L2-cache miss rate | 52.14% | ↓ 33.43% |
| avg L2-cache access time | 102.14 cycles | ↓ 83.43 cycles |
| AMAT | 2.35 | ↓2.08 |
Already by using the most simple next-line prefetching strategy, we can see a significant improvement in the overall AMAT of the system from 2.35 cycles to 2.08 cycles.
| [1] | https://hps.ece.utexas.edu/pub/srinath_hpca07.pdf |